13 Dynamic super‑k‑mer maps
This chapter is partially adapted from (Smith et al., 2024), currently under review.
Yoann Dufresne and Antoine Limasset designed the original prototype. Caleb Smith improved and completed the implementation. We discussed algorithmic improvements together and I wrote experiments scripts. The final section presents my ongoing work on deduplication strategies, not part of the original paper.
Section 4.3 introduced super-k‑mers as a natural byproduct of minimizer-based parsing: consecutive k‑mers sharing a minimizer are grouped into a single string, reducing both the number of objects to index and the memory needed to represent each one. This chapter asks whether super‑k‑mers can serve as the primary representation inside a dynamic k‑mer dictionary, replacing individual k‑mer entries altogether.
Using super‑k‑mers as a full dictionary representation, however, raises two practical challenges. The first is lookup: given a k‑mer, finding it efficiently inside a bucket of super‑k‑mers is not straightforward, because sorting super‑k‑mers lexicographically does not help locate a specific k‑mer. The second is load balancing: minimizer partitions are highly non-uniform on real genomic data, so a handful of very large buckets can dominate overall query time. The main contributions of this chapter are a super‑k‑mer encoding called the interleaved transform that enables binary search within a bucket, and a superbucket scheme that flattens the skewed minimizer distribution. We also place the super‑k‑mer-level approach in relation to the k‑mer-level approach of the previous chapter. The interleaved transform and superbucket scheme are implemented in Brisk, available at https://github.com/Malfoy/Brisk.
13.1 Interleaved super‑k‑mers
13.1.1 Lazy encoding of minimizers
The dictionary is organized as a collection of buckets, one per minimizer: each k‑mer is routed to the bucket of its minimizer and stored implicitly inside one of the super‑k‑mers held there. Since all super‑k‑mers in a bucket share the same minimizer, we can avoid storing that minimizer in each super‑k‑mer. In a maximal super‑k‑mer, the position of the minimizer within the sequence is determined by the super‑k‑mer’s length, so the minimizer can be omitted from the encoding and reconstructed on demand. This lazy encoding lowers the per-k‑mer bit cost: a maximal super‑k‑mer of length 2k - m bases encodes on average (w + 1)/2 k‑mers, giving a ratio of \frac{8(k - m)}{w + 1} = 8 \left(1 - \frac{1}{w+1}\right) bits per k‑mer, which for practical values of k and m is slightly below 8 bits.
To simplify memory management and allow constant-time access to any super‑k‑mer in a list, every super‑k‑mer is allocated at its maximum possible length of 2k - m bases, with bases packed at 2 bits each. The actual extent of each super‑k‑mer is recorded in two small fields, its number of k‑mers and the position of its minimizer within it. The first determines the super‑k‑mer’s total length, and together with the second they fix the number of bases on each side of the minimizer, so positions beyond either side are known and can be treated as a sentinel N when needed. This wastes some space compared to a tightly packed variable-length encoding, but avoids storing per-super‑k‑mer offsets and makes the list amenable to binary search.
13.1.2 The bucket lookup problem
Looking up a k‑mer in its bucket means checking whether it appears in any of the super‑k‑mers stored there. A k‑mer has at most one possible position within a given super‑k‑mer, determined by the relative positions of their minimizers, so each individual comparison is cheap. The difficulty is that buckets can be very large, so a linear scan may end up being costly.
To use binary search, we need to sort the super‑k‑mers. However, standard lexicographic order does not help here: it weights the outermost bases first, which are the least shared among the k‑mers of a super‑k‑mer. The leftmost base of a maximal super‑k‑mer belongs to only one of its k‑mers, the next to two, and so on inward toward the minimizer. Effective binary search needs the discriminating bases to come first, but lexicographic order puts them last.
13.1.3 Interleaving
We propose a base reordering, the interleaved transform, that addresses this. The interleaved form of a super‑k‑mer starts with the minimizer sequence, then alternates between the base immediately to its left and the base immediately to its right, expanding outward until all positions are exhausted. Positions with no base (because the super‑k‑mer does not extend as far in one direction) are filled with the character N. Figure 13.1 shows examples of this transform.

The same transform applies to a k‑mer, viewed as a super‑k‑mer of minimal length, and gives a key property: a k‑mer is contained in a super‑k‑mer if and only if its interleaved form is a prefix of the interleaved super‑k‑mer, with N matching any character. To see why, note that interleaving lists positions outward from the minimizer. A k‑mer contained in a super‑k‑mer extends in both directions no further than the super‑k‑mer does, so its positions come first in the interleaved order. Its bases therefore form a prefix of the super‑k‑mer’s interleaved form, with N filling the positions beyond the k‑mer’s own extent.
Given this property, super‑k‑mers can be sorted lexicographically in their interleaved form and queried by binary search. Each non-N base in the query k‑mer narrows the search space by a factor of up to four, so in most cases the bucket is searched in \mathcal{O}(\log S) steps rather than \mathcal{O}(S). Figure 13.2 illustrates several example searches in a bucket of 32 super‑k‑mers.

13.1.4 Limitations
Because N must match any character, a step involving an N does not reduce the search space, and all four sub-searches must be pursued in parallel from that point. This is harmless when N characters appear only at the end of the query, after the search space has already been reduced to a small number of candidates. It is costly when the minimizer sits at the very start or end of the k‑mer, which places N characters at the beginning of the interleaved form and prevents any early reduction of the search space, as in k‑mer 2 and 3 of Figure 13.2. Such k‑mers degrade to near-linear probing. In practice, the minimizer occupies an interior position for the large majority of k‑mers, so this worst case is rare, arising mainly at sequence boundaries or with very small window sizes.
13.2 Load balancing and superbuckets
13.2.1 Skewed bucket sizes
The interleaved sort provides sublinear lookup within a bucket, but the benefit is diluted when bucket sizes are highly skewed. As established in Chapter 10, minimizer partition sizes are highly non-uniform in practice: a small fraction of minimizers attract a disproportionately large number of super‑k‑mers, and these very large buckets can dominate overall query time even when the average size is moderate. The challenge is to flatten this distribution without breaking the bucket abstraction that makes binary search possible.
13.2.2 Superbuckets via bijective hashing
Applying a hash function to minimizer values would spread them uniformly across buckets, but a surjective hash introduces collisions between distinct minimizers, which is incompatible with an exact structure. We use a bijective hash instead, a reversible permutation over minimizer values, which achieves the same uniformity while letting us recover the original minimizer from its hashed value.
We then group the 4^m possible minimizer buckets into 4^b superbuckets by using the first b bits of each hashed minimizer value as the superbucket index. Each superbucket aggregates 4^{m-b} original buckets, and because the permutation distributes minimizer values uniformly, superbucket sizes are far less skewed than individual bucket sizes. Figure 13.3 shows the successive construction steps.
Within a superbucket, super‑k‑mers from different minimizer buckets remain distinguishable because the full interleaved form starts with the hashed minimizer, which is distinct across buckets. Binary search therefore traverses the minimizer prefix at no extra cost before entering the bucket-specific portion of the sorted list.

13.2.3 Sorting and buffering
Maintaining a strictly sorted list on every insertion would require an \mathcal{O}(S) shift per operation, which becomes expensive as buckets grow. A practical solution is to keep a small unsorted buffer alongside the sorted list. New super‑k‑mers enter the buffer and are scanned linearly until 1000 new entries have accumulated, at which point only the new chunk is sorted and merged into the existing sorted portion via std::inplace_merge. This amortizes sorting cost across many insertions without changing asymptotic lookup time, and avoids ever re-sorting the full list. A larger threshold reduces sorting frequency and speeds up insertion, but slows queries because more candidates must be scanned linearly before the sorted portion is searched. The threshold therefore acts as a tradeoff between insertion and query throughput.
13.3 Super-k‑mer versus k‑mer level representation
The structure presented in Chapter 11 for CBL and the one described in this chapter represent two distinct approaches to organizing a dynamic k‑mer dictionary: one stores each k‑mer as an independent record, the other groups them implicitly inside super‑k‑mers.
In a k‑mer-level structure, each k‑mer is an independent record, and insertion, lookup, and deletion each act on exactly one entry. This conceptual simplicity also enables straightforward optimizations: as discussed in Chapter 12, CBL’s sorted-iterator layout supports efficient in-place set operations while remaining memory-efficient. Because every k‑mer maps to a unique canonical representative, deduplication is structural rather than a separate concern.
In a super‑k‑mer-level structure, k‑mers are stored implicitly inside longer strings. The benefit is that neighboring k‑mers sharing a minimizer are encoded together, and the shared minimizer is not repeated. This gives a lower bits-per-k‑mer footprint, and insertion is streaming-friendly since a new super‑k‑mer is placed directly into the appropriate bucket without decomposing it into individual k‑mers.
The main cost is that the same k‑mer can in principle appear in multiple super‑k‑mers, typically when the same region is covered by overlapping reads. In CBL, deduplication is inherent since each k‑mer maps to a unique necklace and a unique bucket entry. In a super‑k‑mer structure, deduplication requires either a membership test before every insertion (which partially erases the throughput advantage) or a post-processing step that is incompatible with streaming use. This remains an open problem and the primary structural limitation of the super‑k‑mer-level approach. We explore several directions for addressing it in Section 13.5.
A second consideration is the granularity of per-k‑mer operations. In a k‑mer-level structure, the annotation or count associated with a single k‑mer can be updated in isolation. In a super‑k‑mer-level structure, accessing that annotation requires locating the k‑mer within its containing super‑k‑mer, which is a lookup rather than a direct address. For applications where every k‑mer is visited at most once (graph traversal, read mapping), this difference is negligible. For applications that revisit k‑mers frequently or require deletion, the k‑mer-level approach is more natural.
13.4 Performance in practice
We compare Brisk against three reference structures: Jellyfish (Marçais & Kingsford, 2011), a popular k‑mer counter built on an efficient hash table; CBL (Martayan et al., 2024), the dynamic k‑mer set structure discussed in Chapter 11; and the standard Rust HashMap, used as a baseline for general-purpose dynamic dictionaries. Benchmarks were performed on growing collections of bacterial genomes (2^0 to 2^{14} genomes), at two k‑mer sizes: k = 31, a common choice that fits in a 64-bit integer, and k = 59, the maximum size supported by CBL.
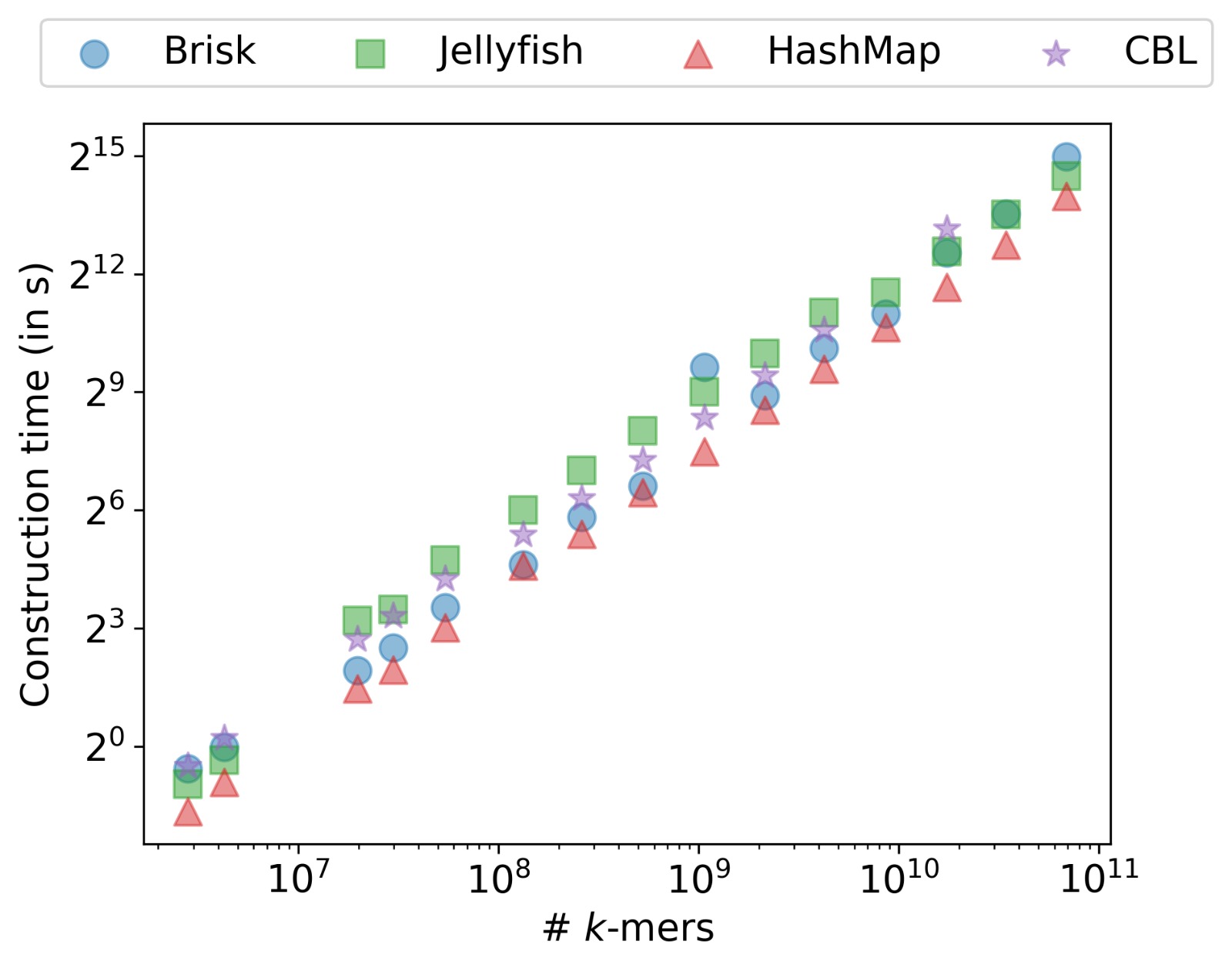
Figure 13.4 shows the memory footprint and construction time across all four tools. For both k‑mer sizes, Brisk uses substantially less memory than the reference structures, and the gap widens at k = 59 as hash-based methods store proportionally more bits per k‑mer while Brisk’s lazy encoding amortizes the cost across each super‑k‑mer. At k = 31, Brisk matches Jellyfish’s throughput. At k = 59 it becomes the fastest of the four.
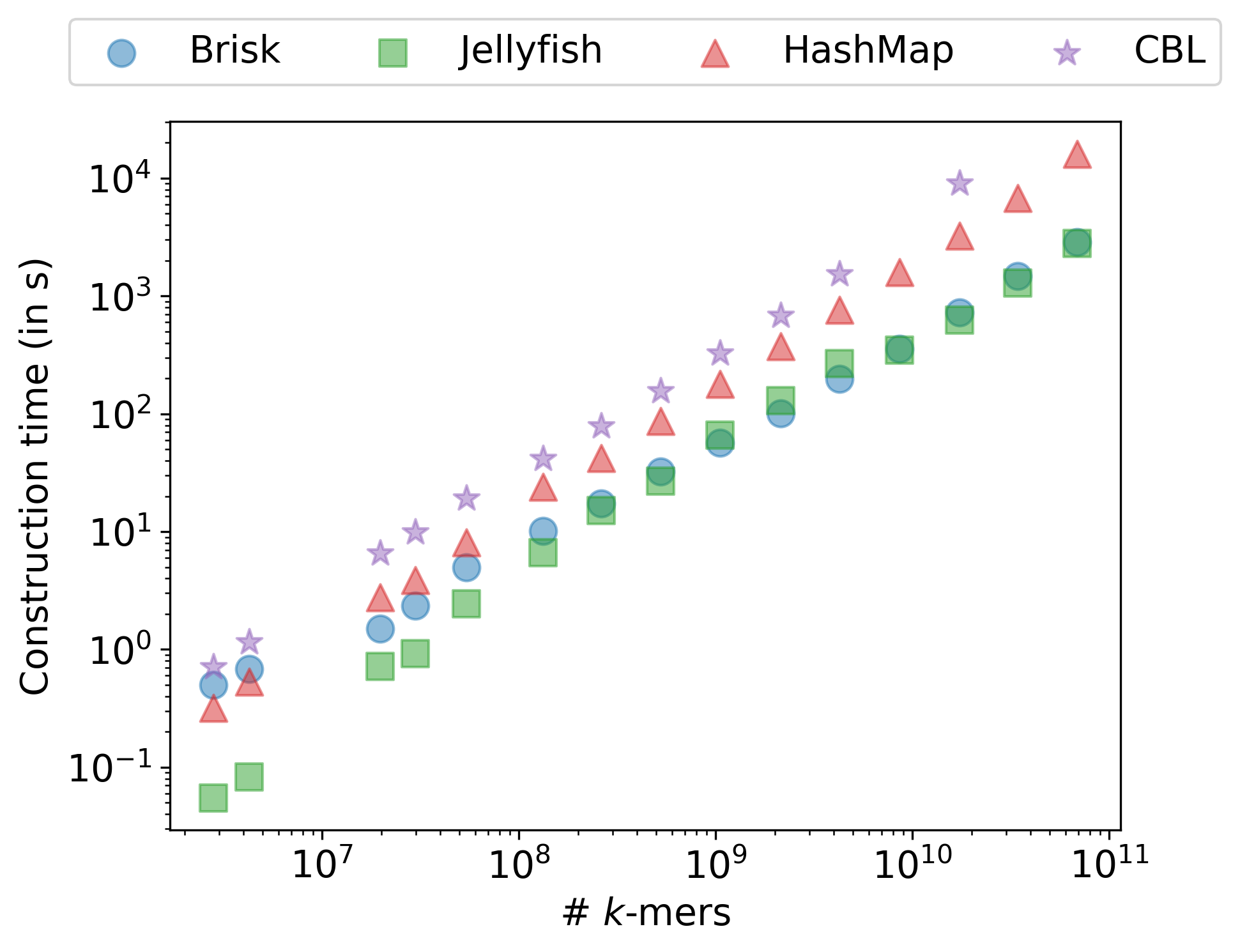
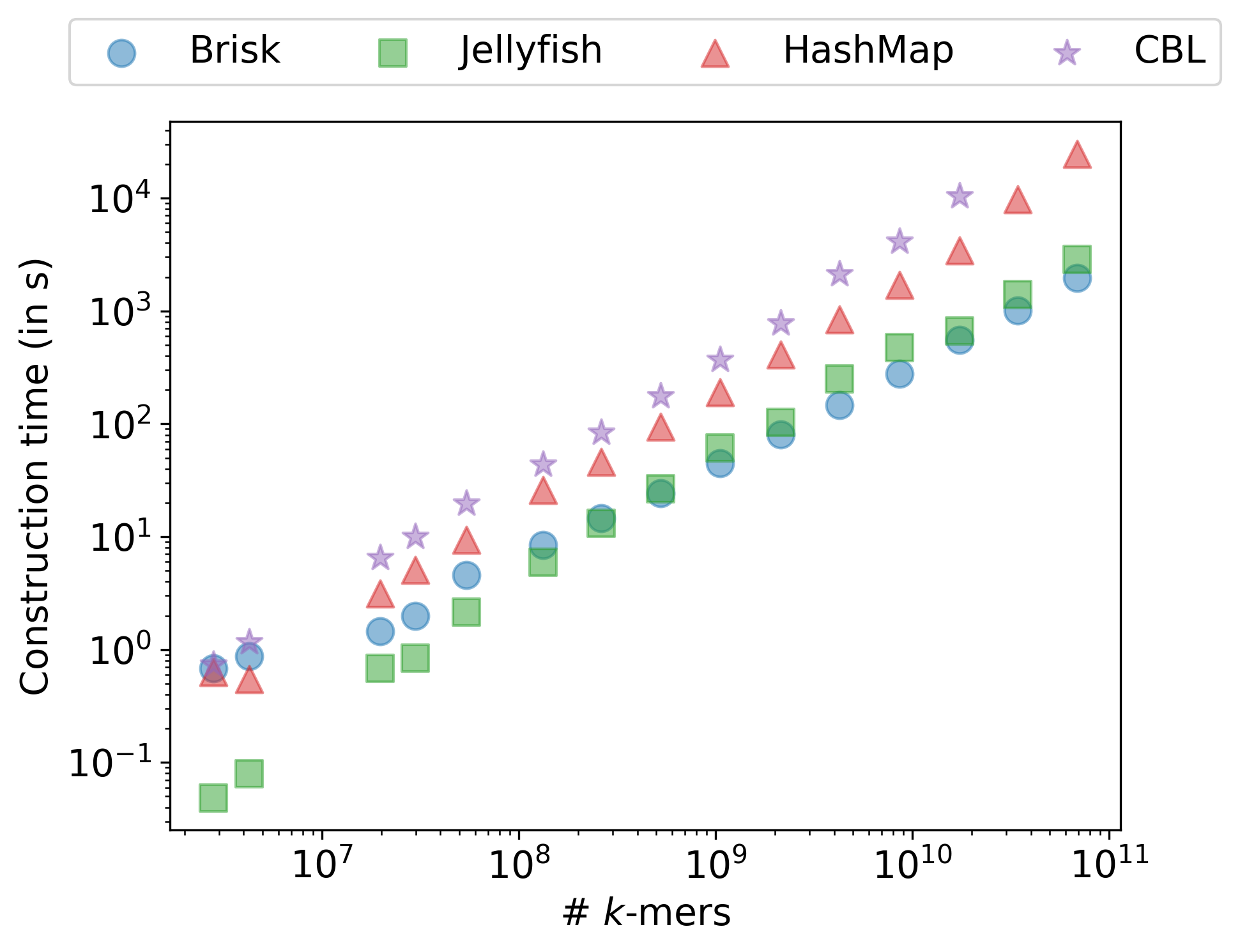
The multi-threaded comparison is not entirely fair, however: Brisk and Jellyfish parallelize, whereas CBL and the Rust HashMap do not. Figure 13.5 isolates this by repeating the benchmark on a single core. The picture is qualitatively similar: Brisk is slightly slower than the Rust HashMap at k = 31 but remains the fastest indexer at k = 59.
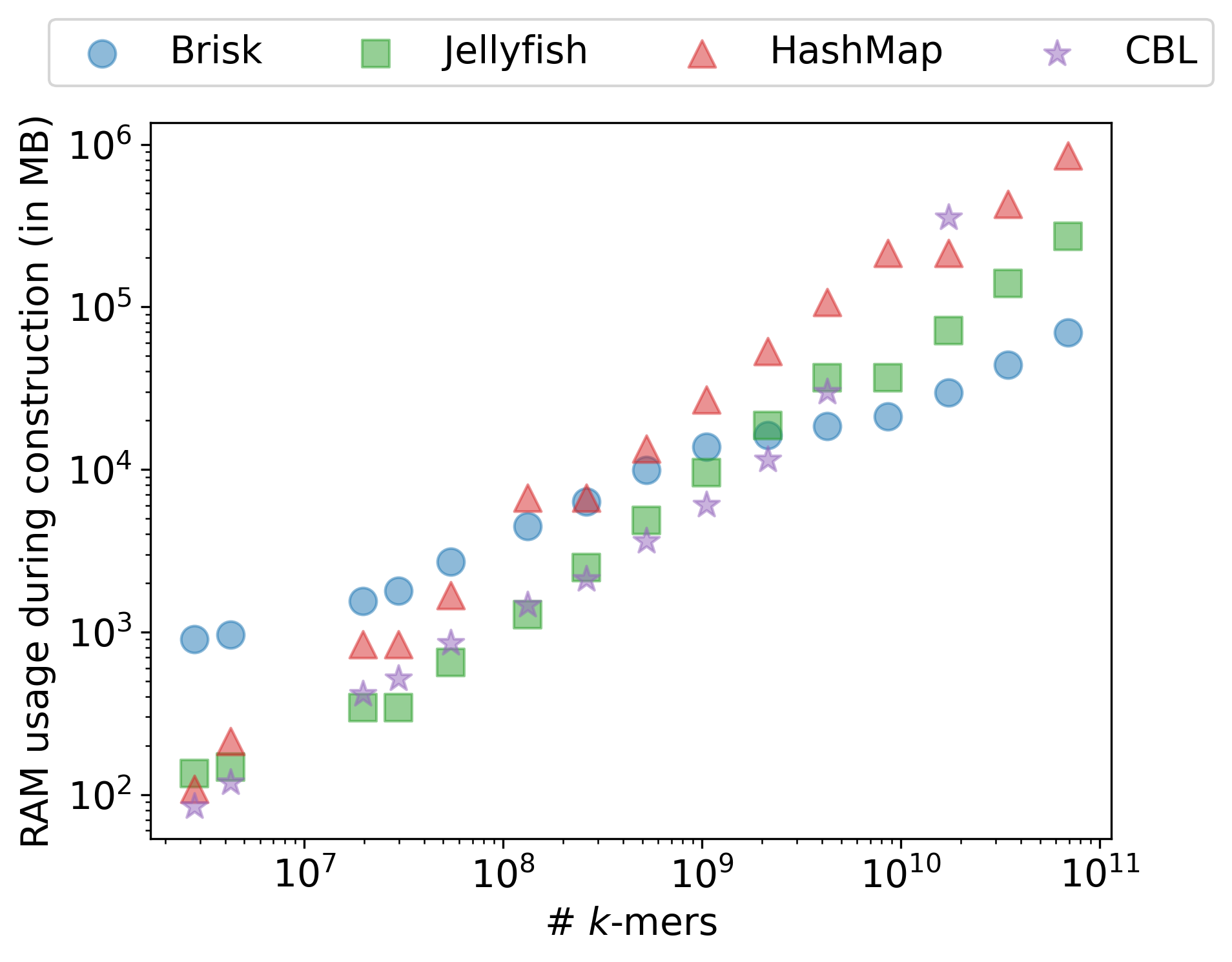
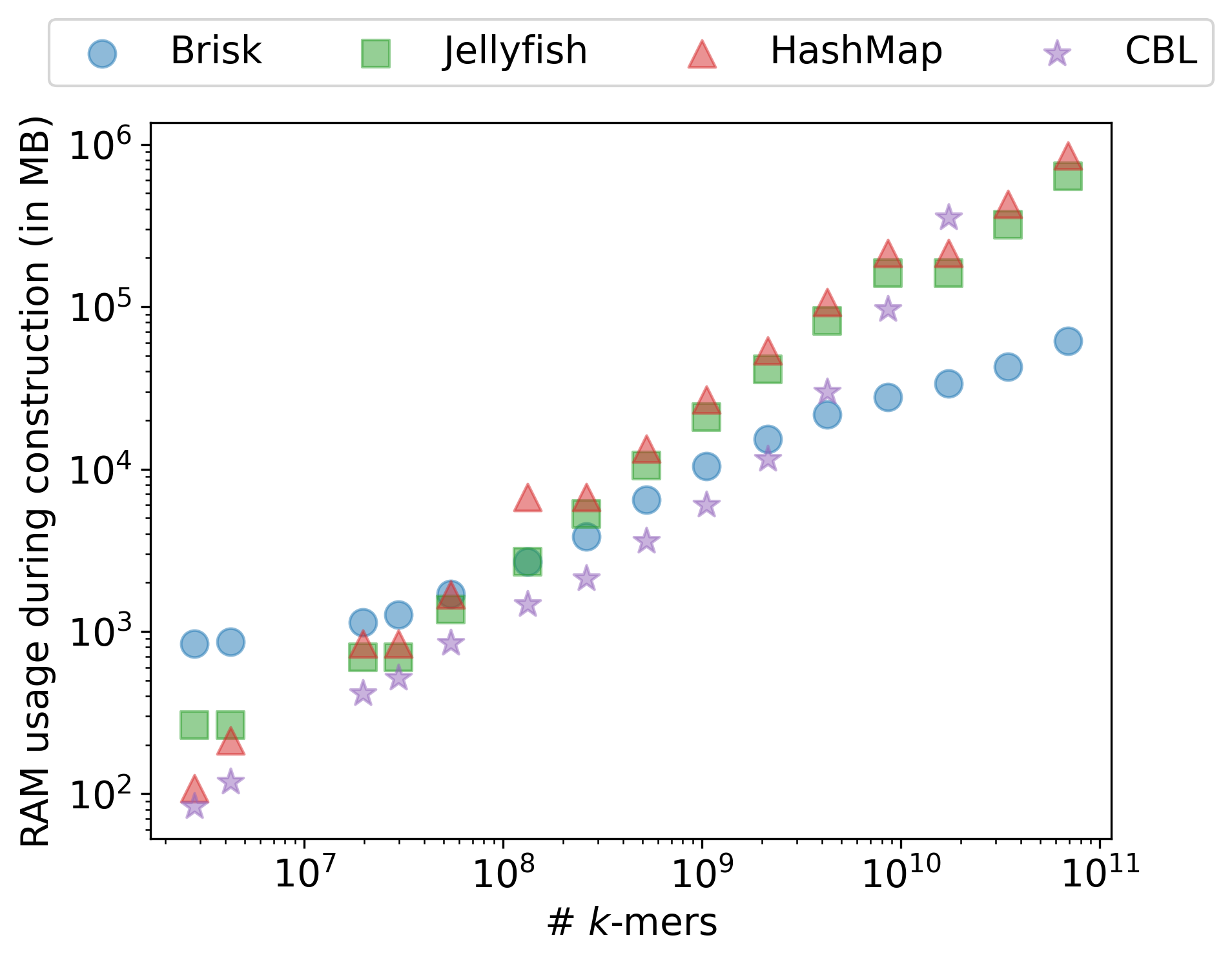
HashMap across growing collections of bacterial genomes, for k = 31 (top) and k = 59 (bottom).
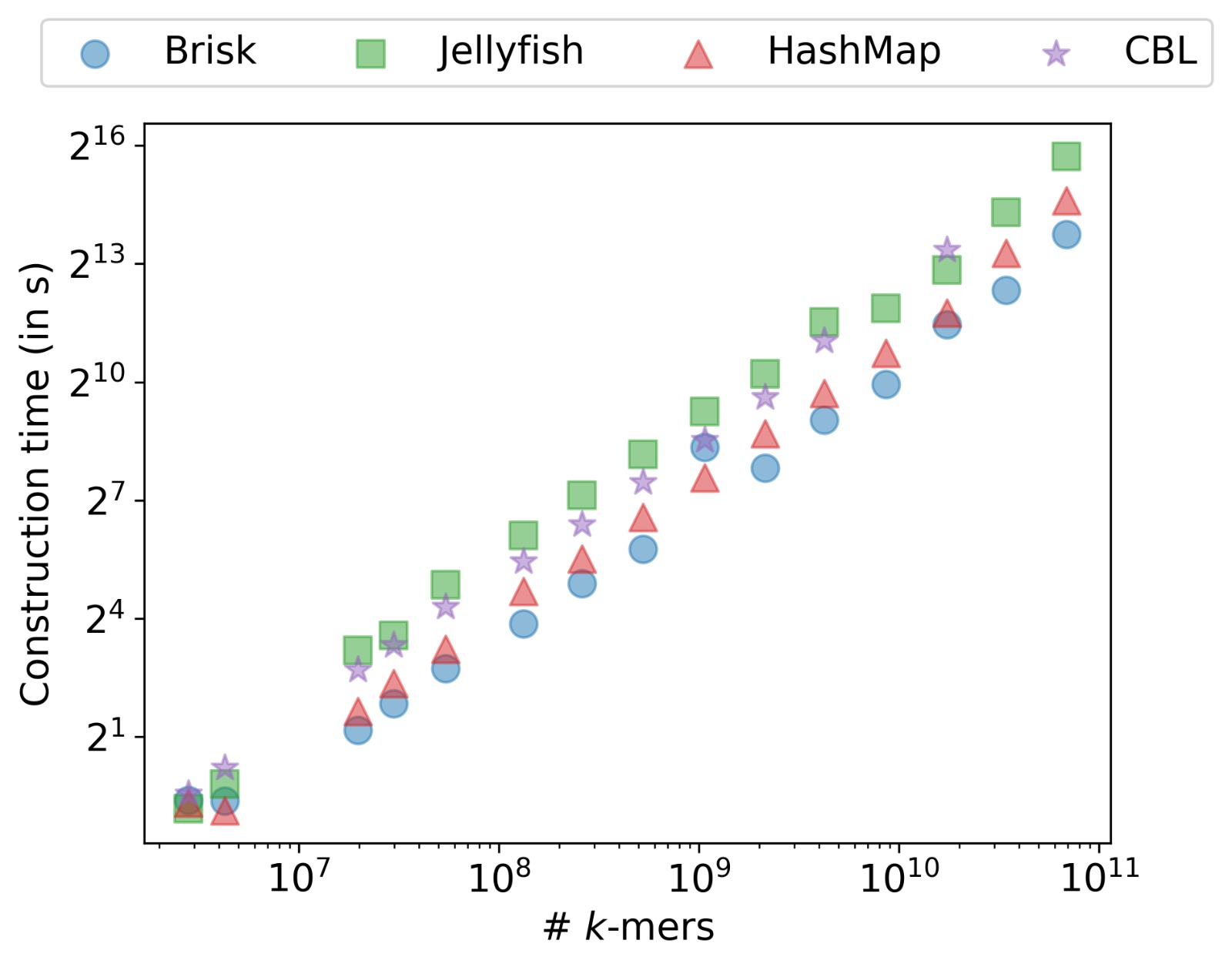
HashMap, controlling for the fact that CBL and Rust HashMap are not parallelized.
13.5 Toward streaming deduplication
The structural limitation of super‑k‑mer dictionaries identified above stems from a single underlying cause: testing which k‑mers of a query are already present requires locating them one by one inside the containing super‑k‑mers. A natural way to bypass this is to express every such operation as a check on the prefixes and suffixes of super‑k‑mers themselves, without materializing individual k‑mers. I am exploring this direction in an ongoing work, prototyping a dynamic super‑k‑mer dictionary that supports on-the-fly deduplication and compaction.
13.5.1 A compact super‑k‑mer representation
The approach I propose packs each super‑k‑mer into a compact two-word encoding. The first word holds the minimizer along with the prefix and suffix lengths. The second word holds the prefix and suffix bases interleaved at the bit-pair level: positions in the word alternate between left bases and right bases, with 2 bits per base. This fits up to 16 bases on each side of the minimizer, giving the constraint k - m \le 16.
In this layout, comparing two super‑k‑mers that share the same minimizer reduces to a single XOR between their encodings, followed by independent leading-zero counts over the left and right halves. The result is a pair (p_L, p_R), the lengths of the common interleaved prefix on each side, computed in a few cycles. The same representation supports constant-time truncation of either side and stitching the left side of one super‑k‑mer with the right side of another. These operations are enough to manipulate super‑k‑mers without ever scanning bases individually.
13.5.2 Coverage-based insertion
Given a query super‑k‑mer Q, the goal at insertion time is to determine which of its k‑mers are already present in the bucket, and only store the new ones. The candidates to compare against are the bucket’s super‑k‑mers that share Q’s minimizer, found by binary search on the sorted prefix of the bucket. For each candidate S, the comparison above returns a pair (p_L, p_R) measuring how far the two super‑k‑mers agree on each side of the minimizer. If p_L + p_R \ge k - m, the agreement spans at least one full k‑mer, so S contains a contiguous range of Q’s k‑mers, determined by where the match starts and ends relative to the minimizer.
The covered ranges from all candidates are combined into a single coverage of Q’s k‑mers. If every k‑mer is covered, the insertion is skipped entirely. Otherwise, for each uncovered range, the insertion either extends an existing super‑k‑mer (using the side-stitching operations above) to incorporate the missing k‑mers, or stores a truncated copy of Q spanning only that range.
Since the bucket is already scanned to find the matching minimizer, computing the coverage adds only a few bit operations per candidate. Insertion-time deduplication therefore preserves the streaming property of the original super‑k‑mer-level approach, with no separate post-processing pass.
13.5.3 Open extensions
My ongoing prototype implements insertion-time deduplication, which already addresses the main structural limitation discussed above. Several extensions remain open work. Deletion has no streaming equivalent of the coverage mechanism, since removing k‑mers from the middle of a super‑k‑mer requires splitting it. Set operations beyond insertion, in particular union and intersection over two indexes, can be expressed in principle as bucket-by-bucket coverage computations, but the interleaved representation does not yet expose the necessary primitives to enumerate shared k‑mers across two sorted super‑k‑mer lists efficiently. Finally, dynamic resizing of the superbucket layout to absorb growing datasets without rebuilding the index is also under investigation.